

Contents
La arquitectura de microservicios, o simplemente microservicios, es un método distintivo de desarrollo de sistemas de software que trata de centrarse en la construcción de módulos de una sola función con interfaces y operaciones bien definidas. Esta tendencia se ha hecho popular en los últimos años a medida que las empresas buscan ser más ágiles y avanzar hacia un DevOps y pruebas continuas.
Los microservicios tienen muchos beneficios para los equipos de Agile y DevOps – como señala Martin Fowler, Netflix, eBay, Amazon, Twitter, PayPal, y otras estrellas de la tecnología han evolucionado de una arquitectura monolítica a la de los microservicios. A diferencia de los microservicios, una aplicación monolítica se construye como una unidad única y autónoma. Esto hace que los cambios en la aplicación sean lentos ya que afecta a todo el sistema. Una modificación hecha a una pequeña sección del código podría requerir la construcción y el despliegue de una versión completamente nueva de software. Escalar funciones específicas de una aplicación, también significa que hay que escalar toda la aplicación.
Los microservicios resuelven estos desafíos de los sistemas monolíticos siendo lo más modular posible. En la forma más simple, ayudan a construir una aplicación como un conjunto de pequeños servicios, cada uno de los cuales se ejecuta en su propio proceso y se despliega de forma independiente. Estos servicios pueden estar escritos en diferentes lenguajes de programación y pueden utilizar diferentes técnicas de almacenamiento de datos. Si bien esto da lugar al desarrollo de sistemas que son escalables y flexibles, requiere una transformación dinámica. Los microservicios suelen estar conectados mediante API, y pueden aprovechar muchas de las mismas herramientas y soluciones que han crecido en el ecosistema de servicios RESTful y de la web. Probar estas APIs puede ayudar a validar el flujo de datos e información a lo largo de su implementación de microservicios.
Comprendiendo la arquitectura de los microservicios
Así como no hay una definición formal del término microservicios, no hay un modelo estándar que se vea representado en cada sistema basado en este estilo arquitectónico. Pero puedes esperar que la mayoría de los sistemas de microservicios compartan algunas características notables.
Las seis características de los microservicios
1) Múltiples componentes
El software construido como microservicios puede, por definición, dividirse en múltiples servicios componentes. ¿Por qué? Para que cada uno de estos servicios pueda ser desplegado, ajustado y luego re-desplegado independientemente sin comprometer la integridad de una aplicación. Como resultado, puede que sólo sea necesario cambiar uno o más servicios distintos en lugar de tener que redistribuir aplicaciones enteras. Pero este enfoque tiene sus desventajas, entre ellas las costosas llamadas remotas (en lugar de las llamadas en proceso), las API remotas de grano grueso y el aumento de la complejidad al redistribuir las responsabilidades entre los componentes.
2) Construido para los negocios
El estilo de los microservicios suele organizarse en torno a las capacidades y prioridades empresariales. A diferencia de un enfoque tradicional de desarrollo monolítico, en el que diferentes equipos tienen cada uno un enfoque específico en, por ejemplo, interfaces, bases de datos, capas de tecnología o lógica del lado del servidor, la arquitectura de microservicios utiliza equipos multifuncionales. Las responsabilidades de cada equipo son hacer productos específicos basados en uno o más servicios individuales que se comunican a través de un bus de mensajes. En los microservicios, un equipo es propietario del producto durante su vida útil, como en la máxima frecuentemente citada de Amazon «Tú lo construyes, tú lo manejas».
3) Enrutamiento simple
Los microservicios actúan de manera similar al clásico sistema UNIX: reciben solicitudes, las procesan y generan una respuesta en consecuencia. Esto es lo contrario de lo que sucede con otros productos como los ESB (Enterprise Service Buses), en los que se utilizan sistemas de alta tecnología para el enrutamiento de mensajes, la coreografía y la aplicación de reglas de negocio. Se podría decir que los microservicios tienen puntos finales inteligentes que procesan la información y aplican la lógica, y tubos tontos a través de los cuales fluye la información.
4) Descentralizado
Dado que los microservicios implican una variedad de tecnologías y plataformas, los métodos de la vieja escuela de gobierno centralizado no son óptimos. La gobernanza descentralizada es favorecida por la comunidad de microservicios porque sus desarrolladores se esfuerzan por producir herramientas útiles que puedan ser utilizadas por otros para resolver los mismos problemas. Al igual que la gobernanza descentralizada, la arquitectura de los microservicios también favorece la gestión descentralizada de los datos. Los sistemas monolíticos utilizan una única base de datos lógica en diferentes aplicaciones. En una aplicación de microservicio, cada servicio suele gestionar su base de datos única.
5) Resistente a las fallas
Al igual que un niño bien formado, los microservicios están diseñados para hacer frente a los fallos. Dado que varios servicios únicos y diversos se comunican entre sí, es muy posible que un servicio pueda fallar, por una u otra razón (por ejemplo, cuando el proveedor no está disponible). En estos casos, el cliente debe permitir que sus servicios vecinos funcionen mientras se inclina de la manera más elegante posible. Sin embargo, la supervisión de los microservicios puede ayudar a prevenir el riesgo de una falla. Por razones obvias, este requisito añade más complejidad a los microservicios en comparación con la arquitectura de sistemas monolíticos.
6) Evolutivo
La arquitectura de los microservicios es un diseño evolutivo y, de nuevo, es ideal para sistemas evolutivos en los que no se puede anticipar completamente los tipos de dispositivos que pueden un día acceder a su aplicación… Muchas aplicaciones comienzan basadas en una arquitectura monolítica, pero a medida que van surgiendo varios requisitos imprevistos, se pueden ir convirtiendo lentamente en microservicios que interactúan sobre una arquitectura monolítica más antigua a través de las API.
Ejemplos de microservicios
Netflix tiene una amplia arquitectura que ha evolucionado de monolítica a SOA. Recibe más de mil millones de llamadas cada día, desde más de 800 tipos diferentes de dispositivos, a su API de streaming de vídeo. Cada llamada a la API provoca unas cinco llamadas adicionales al servicio de backend.
Amazon también ha migrado a los microservicios. Reciben innumerables llamadas de una variedad de aplicaciones -incluidas las aplicaciones que gestionan la API del servicio web, así como el propio sitio web- que habrían sido sencillamente imposibles de gestionar con su antigua arquitectura de dos niveles.
El sitio de subastas eBay es otro ejemplo que ha pasado por la misma transición. Su aplicación central comprende varias aplicaciones autónomas, cada una de las cuales ejecuta la lógica comercial para diferentes áreas funcionales.
Pros y contras de los microservicios
Los microservicios no son una bala de plata, y al implementarlos expondrá la comunicación, el trabajo en equipo y otros problemas que antes estaban implícitos pero que ahora se ven forzados a salir a la luz. Pero las Puertas de enlace de la API en los Microservicios pueden reducir enormemente el tiempo y el esfuerzo de construcción y control de calidad.
Un problema común implica compartir el esquema/lógica de validación entre servicios. Lo que A requiere para considerar algunos datos como válidos no siempre se aplica a B, si B tiene necesidades diferentes. La mejor recomendación es aplicar el versionado y distribuir el esquema en las bibliotecas compartidas. Los cambios en las bibliotecas se convierten entonces en discusiones entre equipos. Además, con el versionado fuerte vienen las dependencias, que pueden causar más gastos generales. La mejor práctica para superar esto es planificar en torno a la compatibilidad hacia atrás, y aceptar pruebas de regresión de servicios/equipos externos. Estos te incitan a tener una conversación antes de interrumpir el proceso de negocio de otra persona, no después.
Como con cualquier otra cosa, si la arquitectura de microservicios es o no adecuada para usted depende de sus requerimientos, porque todos tienen sus pros y contras. Aquí hay un rápido resumen de lo bueno y lo malo:
Pros
La arquitectura de microservicios da a los desarrolladores la libertad de desarrollar y desplegar servicios de forma independiente
Un microservicio puede ser desarrollado por un equipo bastante pequeño
Los códigos de los diferentes servicios pueden estar escritos en diferentes idiomas (aunque muchos profesionales lo desaconsejan)
Fácil integración y despliegue automático (utilizando herramientas de integración continua de código abierto como Jenkins, Hudson, etc.)
Fácil de entender y modificar para los desarrolladores, por lo que puede ayudar a un nuevo miembro del equipo a ser productivo rápidamente
Los desarrolladores pueden hacer uso de las últimas tecnologías
El código está organizado en torno a las capacidades comerciales
Inicia el contenedor de la web más rápidamente, por lo que el despliegue es también más rápido
Cuando se requiere un cambio en una determinada parte de la aplicación, sólo se puede modificar y redistribuir el servicio relacionado, sin necesidad de modificar y redistribuir toda la aplicación.
Mejor aislamiento de las fallas: si un microservicio falla, el otro seguirá funcionando (aunque un área problemática de una aplicación de monolito puede poner en peligro todo el sistema)
Fácil de escalar e integrar con servicios de terceros
No hay un compromiso a largo plazo con la pila de tecnología
Contras
Debido al despliegue distribuido, las pruebas pueden volverse complicadas y tediosas
El aumento del número de servicios puede dar lugar a barreras de información
La arquitectura aporta una complejidad adicional ya que los desarrolladores tienen que mitigar la tolerancia a fallos, la latencia de la red y tratar con una variedad de formatos de mensajes, así como el equilibrio de carga.
Al ser un sistema distribuido, puede dar lugar a la duplicación de esfuerzos
Cuando el número de servicios aumenta, la integración y la gestión de productos enteros puede complicarse
Además de las diversas complejidades de la arquitectura monolítica, los desarrolladores tienen que lidiar con la complejidad adicional de un sistema distribuido
Los desarrolladores tienen que poner un esfuerzo adicional en la aplicación del mecanismo de comunicación entre los servicios
La tramitación de los casos de uso que abarcan más de un servicio sin utilizar transacciones distribuidas no sólo es difícil, sino que también requiere comunicación y cooperación entre diferentes equipos
Cómo funciona la arquitectura de microservicios
1) Los monolitos y la ley de Conway
Para empezar, exploremos la Ley de Conway, que dice: «Las organizaciones que diseñan sistemas… están obligadas a producir diseños que son copias de las estructuras de comunicación de estas organizaciones.»
Imaginen a la Compañía X con dos equipos: Apoyo y Contabilidad. Instintivamente, separamos las actividades de alto riesgo; sólo es difícil decidir las responsabilidades como los reembolsos de los clientes. Considere cómo podríamos responder a preguntas como «¿Tiene el equipo de Contabilidad suficiente gente para procesar tanto los reembolsos de los clientes como los créditos?» o «¿No sería un mejor resultado que nuestro personal de Soporte pudiera aplicar créditos y tratar con clientes frustrados?» Las respuestas se resuelven con la nueva política de la Compañía X: Soporte puede aplicar un crédito, pero Contabilidad tiene que procesar un reembolso para devolver el dinero a un cliente. Las funciones y responsabilidades en este sistema interconectado se han dividido con éxito, mientras se obtiene la satisfacción del cliente y se minimizan los riesgos.
Asimismo, al principio del diseño de cualquier aplicación de software, las empresas suelen reunir un equipo y crear un proyecto. Con el tiempo, el equipo crece y se completan múltiples proyectos sobre la misma base de código. En la mayoría de los casos, esto lleva a proyectos que compiten entre sí: a dos personas les resultará difícil trabajar con propósitos cruzados en la misma área de código sin introducir compensaciones. Y agregar más personas a la ecuación sólo empeora el problema. Como dice Fred Brooks, nueve mujeres no pueden tener un bebé en un mes.
Además, en la Compañía X o en cualquier equipo de desarrollo, las prioridades cambian con frecuencia, lo que resulta en problemas de gestión y comunicación. El elemento de mayor prioridad del mes pasado puede haber causado que nuestro equipo se esfuerce por enviar el código, pero ahora un usuario está reportando un problema, y ya no tenemos tiempo para resolverlo debido a la prioridad de este mes. Esta es la razón más convincente para adoptar SOA, incluyendo la variedad de microservicios. Los enfoques orientados a los servicios reconocen las fricciones involucradas entre la gestión del cambio, el conocimiento del dominio y los profesionales de los negocios, permitiendo a los equipos de desarrollo separarlas y abordarlas explícitamente. Por supuesto, esto en sí mismo es un compromiso -requiere coordinación- pero permite centralizar las fricciones e introducir la eficiencia, en lugar de sufrir un gran número de pequeñas ineficiencias.
Lo más importante es que la implementación inteligente de una arquitectura SOA o de microservicio te obliga a aplicar el principio de separación de interfaces. Debido a la naturaleza conectada de los sistemas maduros, cuando se aíslan cuestiones de interés, el enfoque típico es encontrar una unión o punto de comunicación y luego dibujar una línea de puntos entre dos mitades del sistema. Sin embargo, sin pensarlo bien, esto puede llevar a la creación accidental de dos monolitos más pequeños pero crecientes, ahora conectados con algún tipo de puente. La consecuencia de esto puede ser el abandono de un código importante en el lado equivocado de una barrera: El Equipo A no se molesta en cuidarlo, mientras que el Equipo B lo necesita, así que lo reinventan.
2) Microservicios: Evitar los monolitos
Hemos nombrado algunos problemas que surgen comúnmente; ahora comencemos a buscar algunas soluciones.
¿Cómo desplegar servicios relativamente independientes pero integrados sin generar monolitos accidentales? Bueno, suponga que tiene una aplicación grande, como en la muestra de nuestra Compañía X más abajo, y está dividiendo la base de código y los equipos a escala. En lugar de encontrar una sección entera de una aplicación para dividirla, puedes buscar algo en el borde del gráfico de la aplicación. Puedes decir qué secciones son estas porque nada depende de ellas. En nuestro ejemplo, las flechas que apuntan a Impresora y Almacenamiento sugieren que son dos cosas que pueden ser fácilmente removidas de nuestra aplicación principal y abstraídas. Imprimir un trabajo o una factura es irrelevante; una impresora sólo quiere datos imprimibles. Convirtiendo estos -Impresora y Almacenamiento- en servicios externos se evita el problema de los monolitos al que se ha aludido antes. También tiene sentido, ya que se utilizan varias veces, y hay poco que se pueda reinventar. Los casos de uso son bien conocidos por la experiencia pasada, así que se puede evitar la eliminación accidental de la funcionalidad de las teclas.
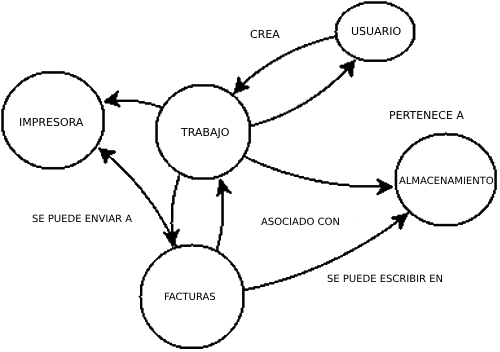
3) Objetos de servicio y datos de identificación
Entonces, ¿cómo pasamos de los monolitos a los servicios? Una forma es a través de los objetos de servicio. Sin eliminar el código de tu aplicación, efectivamente sólo comienzas a estructurarlo como si fuera completamente externo. Para ello, primero tendrás que diferenciar las acciones que se pueden hacer y los datos que están presentes como entradas y salidas de esas acciones. Considere el código que aparece a continuación, con una noción de hacer algo útil y un estado de esa tarea
class to model a core transaction and execute it
class Trabajo
def initialize
@status = ‘En Cola’
end
def haz_trabajo
….
@status = ‘Acabado’
end
def finished?
return @status == ‘Acabado’
end
def ready?
return @status == ‘En Cola’
end
end
Para preparar esto para que empiece a parecer un microservicio, ¿qué es lo siguiente?
# Servicio para realizar un trabajo y modificar un estado
class JobService
def haz_trabajo(job_status)
….
job_status.finish!
return job_status
end
end
# A model of our Job’s status
class JobStatus
def initialize
@status = ‘En Cola’
end
def finished?
return @status == ‘Acabado’
end
def ready?
return @status == ‘En Cola’
end
def finish!
@status = ‘Acabado’
end
end
Ahora hemos distinguido dos clases distintas: una que modela los datos, y otra que realiza las operaciones. Lo importante es que nuestra clase JobService tiene poco o ningún estado… puedes llamar a las mismas acciones una y otra vez, cambiando sólo los datos, y esperar obtener resultados consistentes. Si JobService de alguna manera comenzara a tener lugar en una red, a nuestra aplicación, que de otra manera sería monolítica, no le importaría. Cambiar este tipo de clases a una biblioteca, y sustituir la implementación anterior por un cliente de red, le permitiría transformar el código existente en un servicio externo escalable.
4) Coordinación y Tubos Tontos
Ahora veamos más de cerca lo que hace que algo sea un microservicio a diferencia de un SOA tradicional.
Tal vez la distinción más importante son los efectos secundarios. Los microservicios los evitan. Para ver por qué, veamos un enfoque más antiguo: Tubos de Unix.
ls | wc -l
Arriba, dos programas están encadenados: el primero lista todos los archivos de un directorio, el segundo lee el número de líneas de un flujo de entrada. Imagine escribir un programa comparable, y luego tener que modificarlo en el siguiente:
ls | menos
La composición de pequeñas piezas de funcionalidad se basa en resultados repetibles, un mecanismo estándar de entrada y salida, y un código de salida de un programa para indicar el éxito o la falta de éste. Sabemos que esto funciona a partir de la evidencia de la observación, y también sabemos que un tubo Unix es una interfaz «tonta» porque no tiene declaraciones de control. El tubo aplica SRP empujando los datos de A a B, y depende de los miembros del tubo decidir si la entrada es inaceptable.
Volvamos a los sistemas de trabajo y facturación de la Compañía X. Cada uno de ellos controla una transacción y pueden ser utilizados juntos o por separado: Se pueden crear facturas para los trabajos, se pueden crear trabajos sin una factura y se pueden crear facturas sin un trabajo. A diferencia de los comandos shell de Unix, los sistemas que poseen trabajos y facturas tienen sus propios usuarios que trabajan de forma independiente. Pero sin recurrir a una política, es imposible hacer cumplir las reglas para cualquiera de los sistemas a nivel mundial.
Digamos que queremos extraer las operaciones clave que pueden ejecutarse repetidamente: los servicios para enviar una factura, mutar el estado de un trabajo y mutar el estado de una factura. Estos están completamente separados de la tarea de persistir los datos.
El usuario crea una factura manual
Añade datos a la factura, estado creado
– Invoca a BillingPolicyService para determinar cuándo se debe pagar una factura por un cliente determinado
La factura se emite al cliente
Persiste al servicio de datos de la factura, estado enviado
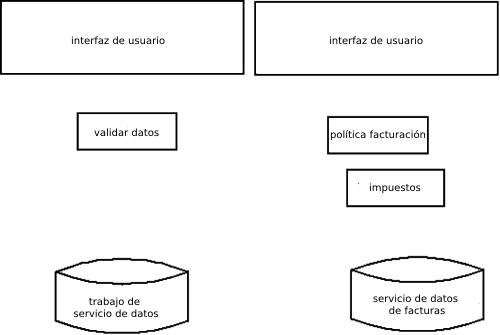
El usuario termina un trabajo, creando una factura
Valida que el trabajo se pueda completar
Añade datos a la factura, estado creado
-Invoca a BillingPolicyService para determinar cuando una factura es pagadera para un cliente determinado
La factura se emite al cliente
Persiste al servicio de datos de la factura, estado enviado
Los pasos relacionados con el cálculo de la factura son idempáticos, y entonces es trivial componer un borrador de la factura o previsualizar las cantidades a pagar por el cliente aprovechando nuestros nuevos microservicios dedicados.
A diferencia de la SOA tradicional, la diferencia aquí es que tenemos detalles de bajo nivel expuestos a través de una interfaz simple, en comparación con una llamada de alto nivel a la API que podría ejecutar una acción de negocio completa. Con una API de alto nivel, de hecho, se hace difícil recablear los pequeños componentes juntos, ya que el diseñador del servicio ha eliminado muchas de las costuras o opciones que podemos tomar al proporcionar una interfaz de una sola vez.
En este punto, la repetición de la lógica, la política y las reglas de negocio lleva a muchos a empujar tradicionalmente esta complejidad a un bus de servicios o a una herramienta de orquestación de flujo de trabajo singular y centralizada. Sin embargo, la ventaja crucial de la arquitectura de microservicios no es que nunca compartamos reglas/procesos/políticas de negocio, sino que los empujamos a paquetes discretos, alineados con las necesidades del negocio. Esto no sólo significa que la política está distribuida, sino que también significa que se pueden cambiar los procesos de negocio sin riesgo.
SOA vs. Microservicios
«Esperen un minuto», algunos de ustedes pueden estar murmurando sobre su café matutino, «¿no es este otro nombre para SOA?» La Arquitectura Orientada a Servicios (SOA) surgió durante los primeros años de este siglo, y la arquitectura de microservicios (abreviada por algunos como MSA) tiene varias similitudes. La SOA tradicional, sin embargo, es un marco más amplio y puede significar una gran variedad de cosas. Algunos defensores de los microservicios rechazan la etiqueta SOA por completo, mientras que otros consideran que los microservicios son simplemente una forma ideal y refinada de SOA. En cualquier caso, creemos que hay diferencias suficientemente claras para justificar un concepto de «microservicio» distinto (al menos como una forma especial de SOA, como ilustraremos más adelante).
El modelo típico de SOA, por ejemplo, suele tener ESB más dependientes, con microservicios que utilizan mecanismos de mensajería más rápidos. La SOA también se centra en la programación imperativa, mientras que la arquitectura de los microservicios se centra en un estilo de programación de factor de respuesta. Además, los modelos SOA tienden a tener una base de datos relacional de gran tamaño, mientras que los microservicios suelen utilizar bases de datos NoSQL o micro-SQL (que pueden conectarse a bases de datos convencionales). Pero la verdadera diferencia tiene que ver con los métodos de arquitectura utilizados para llegar a un conjunto integrado de servicios en primer lugar.
Dado que todo cambia en el mundo digital, las técnicas de desarrollo ágiles que pueden seguir el ritmo de las demandas de la evolución del software son inestimables. La mayoría de las prácticas utilizadas en la arquitectura de microservicios provienen de desarrolladores que han creado aplicaciones de software para grandes organizaciones empresariales, y que saben que los usuarios finales de hoy en día esperan experiencias dinámicas pero consistentes en una amplia gama de dispositivos. Las aplicaciones basadas en la nube, escalables, adaptables, modulares y de rápido acceso tienen una gran demanda. Y esto ha llevado a muchos desarrolladores a cambiar su enfoque.
El futuro de la arquitectura de microservicios
Independientemente de que la arquitectura de microservicios se convierta o no en el estilo preferido de los desarrolladores en el futuro, es claramente una idea potente que ofrece serios beneficios para el diseño y la implementación de aplicaciones empresariales. Muchos desarrolladores y organizaciones, sin utilizar nunca el nombre o incluso etiquetar su práctica como SOA, han estado utilizando un enfoque para aprovechar las API que podrían clasificarse como microservicios.
También hemos visto una serie de tecnologías existentes que tratan de abordar partes de los problemas de segmentación y comunicación que los microservicios pretenden resolver. SOAP hace bien en describir las operaciones disponibles en un punto final dado y dónde descubrirlo a través de WSDL. UDDI es teóricamente un buen paso hacia la publicidad de lo que un servicio puede hacer y dónde puede ser encontrado. Pero estas tecnologías se han visto comprometidas por una implementación relativamente compleja, y tienden a no ser adoptadas en proyectos más nuevos. Los servicios basados en REST se enfrentan a los mismos problemas, y aunque se pueden usar WSDLs con REST, no se hace de forma generalizada.
Asumiendo que el descubrimiento es un problema resuelto, compartir el esquema y el significado a través de aplicaciones no relacionadas sigue siendo una propuesta difícil para cualquier cosa que no sean los microservicios y otros sistemas SOA. Tecnologías como RDFS, OWL y RIF existen y están estandarizadas, pero no se usan comúnmente. JSON-LD y Schema.org ofrecen un vistazo de lo que es una red abierta completa que comparte definiciones, pero éstas aún no han sido adoptadas en las grandes empresas privadas.
Sin embargo, el poder de las definiciones compartidas y estandarizadas está haciendo avances dentro del gobierno. Tim Berners Lee ha estado abogando ampliamente por Linked Data. Los resultados son visibles a través de data.gov y data.gov.uk, y puede explorar el gran número de conjuntos de datos disponibles como datos vinculados bien descritos aquí. Si se puede acordar un gran número de definiciones estandarizadas, los siguientes pasos son más probables hacia los agentes: pequeños programas que orquestan microservicios de un gran número de proveedores para lograr ciertos objetivos. Cuando se añade la creciente complejidad y los requisitos de comunicación de las aplicaciones SaaS, los vestidos y el Internet de las cosas en el panorama general, está claro que la arquitectura de microservicios probablemente tiene un futuro muy brillante por delante.